Using ping to test AWS VPC network latency within a single region
The code for this experiment is available here.
Overview
I am demonstrating how to measure network latency in AWS VPC network with ping.
Although ping is not primarily made for the latency benchmarking purpose, I use ping because it's widely known, robust, and I didn't find any other prevalent network latency measurement tool. (Let me know if there is actually a better tool) Indeed, some people and tools use ping for latency benchmarking. Flent is one such example, which uses ping as an underlying tool to measure latency.
Performing low-level network benchmarking by yourself gives you benefits, because cloud vendors like AWS don't provide, or at least keep updating official network benchmarking results, even though they could keep updating their network infrastructure and devices. Also, knowing the low-level component's performance characteristics is key to analyze the bottlenecks of higher-level, system-wide performance.
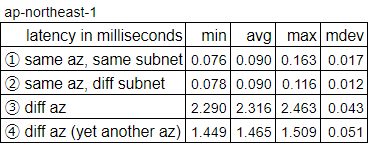
Here are the brief results of my AWS VPC latency benchmarking in a single region.
From here, I'll review AWS VPC network to explain the motivation for this test, then cover the steps I did.
Anatomy of AWS VPC network, regions and availability zones
Skip this section if you are familiar with AWS VPC.
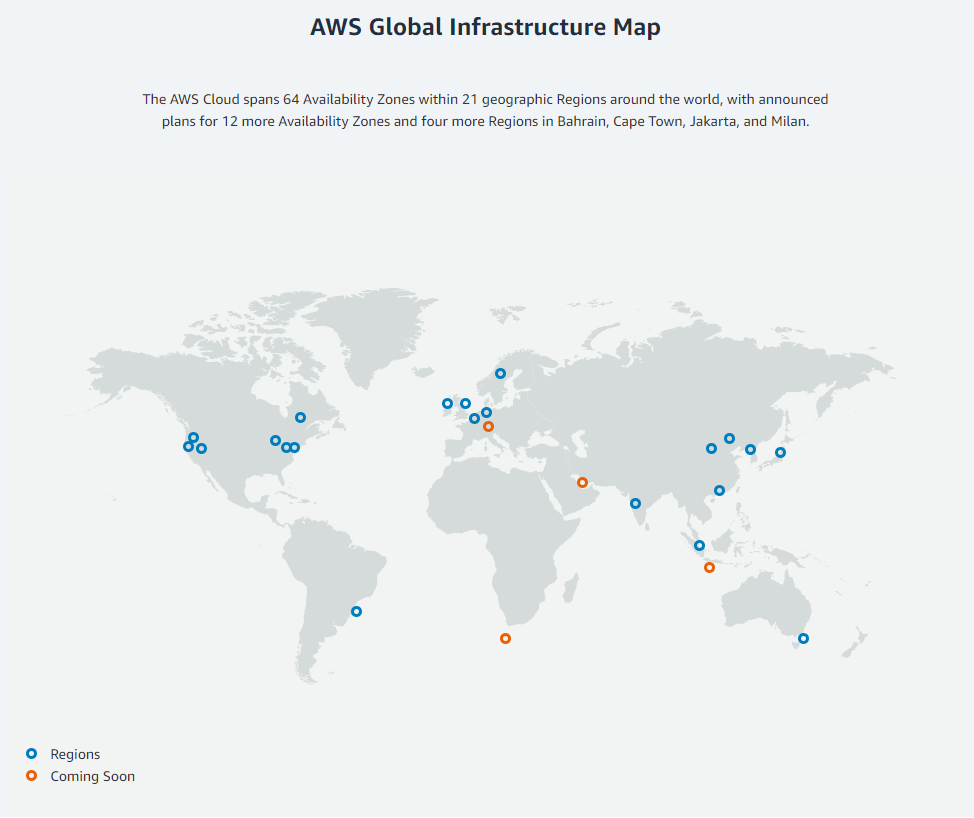
The above picture is from AWS's official page. AWS VPC (Virtual Private Cloud) is regional, not global. That means, When you provision your VPC network, you firstly have to select one AWS region from possible choices.
Then inside a region, there are availability zones, which are connected through low-latency links.
Each Region is completely independent. Each Availability Zone is isolated, but the Availability Zones in a Region are connected through low-latency links.
So, my immediate interest is what the latency is between availability zones, and how slower it is compared to the latency within the same availability zone. That is interesting to me because the application deployment pattern can be affected.
Let me illustrate that using an application deployment with servers and a DB cluster like below.
An application like above needs to be deployed within a VPC, and the region should be specified for the VPC. My default region is Tokyo, ap-northeast-1. And I set up a single VPC in this region.
There could be two typical deployment patterns possible as in the below two pictures.
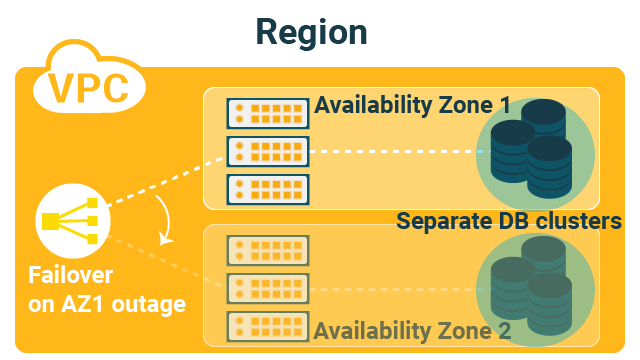
This first pattern has no communication between availability zone 1 and 2. The servers and databases are completely separated between the availability zones. Unless there is the outage of an availability zone 1, nothing in the availability zone 2 is used. (hot stand-by)
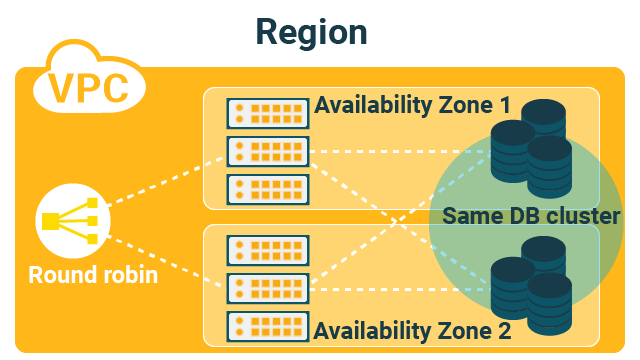
The second pattern allows communication between the availability zones. if the latency between the availability zones is low, as the databases in the two availability zones form a single DB cluster, and there is communication between the two availability zones.
The first pattern has difficulty in data replication, because you need to think about data replication between the separate clusters. Data recovery is crucial upon the outage of an availability zone. In the second pattern, you only need to replicate the data within the same cluster which is generally easier.
The latency between availability zones can affect your deployment pattern in VPC, and certain operations, in this case data replication, is difficult in some patterns.
Test structure of regions, availability zones, and subnets
From here, I'll explain the deployment structure for this test.
In AWS, there is also a subnet, which is more like a logical grouping of IP addresses, compared to a region and an availability zone which ties to physical locations.
Subnet belongs to a single availability zone, so eventually, computing resources in a subnet are in a single availability zone. (See the below picture) For this test, I use raw EC2 instances (not EKS or ECS), ping from one EC2 instance to another, and repeating it to cover all availability zones. No database is involved unlike the pictures in the previous section.
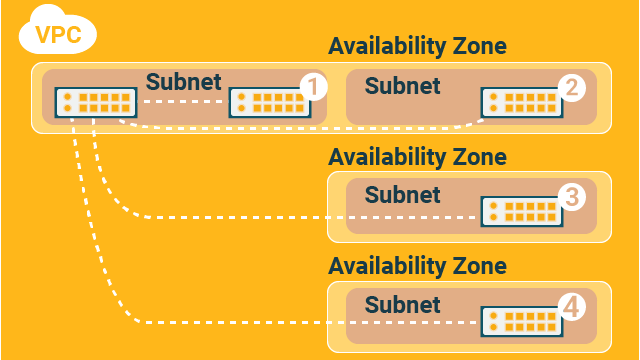
There are four pairs (connectoins) as numbered in the above picture. They are pinging from the origin EC2 instance (top-left in the picture) to:
- EC2 within the same subnet, in the same availability zone
- EC2 in a different subnet, in the same availability zone
- EC2 in a different availability zone
- EC2 in yet another availability zone
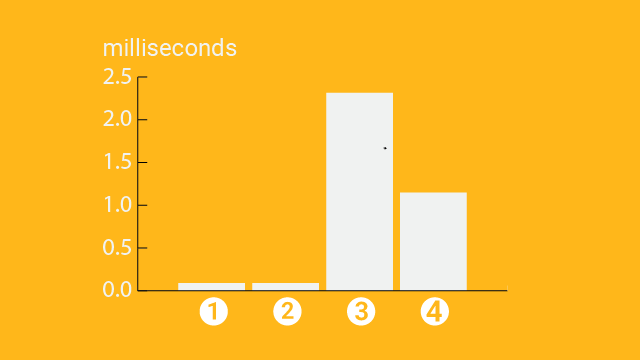
The above graph illustrates the test results.
To explain more details about the results, when you run ping, it gives output like this:
> ping -c 30 10.107.3.5
PING 10.107.3.5 (10.107.3.5) 56(84) bytes of data.
64 bytes from 10.107.3.5: icmp_seq=1 ttl=255 time=1.50 ms
64 bytes from 10.107.3.5: icmp_seq=2 ttl=255 time=1.46 ms
...
...
64 bytes from 10.107.3.5: icmp_seq=30 ttl=255 time=1.49 ms
--- 10.107.3.5 ping statistics ---
30 packets transmitted, 30 received, 0% packet loss, time 29044ms
rtt min/avg/max/mdev = 1.449/1.465/1.509/0.051 msSummarizing the results from the four cases, I got this table. This is same as I provided at the beginning of this article:
Interestingly, the case 3 and 4 gave different letency numbers. Probably there is difference in the physical distance between these cases, but I don't even know if the availability zones are in the same data center, or in different data centers.
Conclusion
The code for this experiment is available here.
There was a millisecond order difference in the latency numbers, comparing connections across different availability zones. So, if the millisecond latency difference matters, only the first application deployment pattern I explained earlier is possible. If such magnitude of latency doesn't matter, the second pattern could be possible.
However, better not to trust someone else’s (including mine!) benchmark results blindly. More import thing is that now you can perform the same benchmarking by yourself. The source code is available at GitHub, and the test structure was already explained. The benchmarking results can be different if you perform the same test:
- in a different region
- on a different day
- in a later year where network infrastructure is possibly upgraded
- with different EC2 instance types
- and whatever changes that could affect the results
By performing benchmarking on your own, you get a better understanding of the performance characteristics of the low-level components. And that forms a basis for understanding higher-level, system-wide performance analysis.
In the next article, I will write about testing latency across AWS regions. I will also cover throughput benchmarking in the AWS network in other articles. I hope you find those interesting and useful.
References
https://aws.amazon.com/about-aws/global-infrastructure/ https://aws.amazon.com/about-aws/global-infrastructure/regions_az/