Akka HTTP request streaming

In the previous article, Akka HTTP response streaming, I covered HTTP response streaming to send chunk-by-chunk HTTP body to the client.
Then I am going to introduce the oppsite, which is HTTP request streaming. That is also described in the official Akka HTTP doc in the Consuming JSON Streaming uploads section.
For thoese who are interested, full source code is available here , with instruction to run the example.
To follow the example, you need this in your build.sbt:
libraryDependencies ++= Seq(
"com.typesafe.akka" %% "akka-http" % "10.1.3",
"com.typesafe.akka" %% "akka-stream" % "2.5.12",
"com.typesafe.akka" %% "akka-http-spray-json" % "10.1.3",
"io.spray" %% "spray-json" % "1.3.4"
)The asSourceOf directive
In Akka HTTP Routing DSL, there is a convenient directive for HTTP request streaming, which is asSourceOf.
def route(): Route = post {
entity(asSourceOf[T]) { source => //Source[T, NotUsed]
val result: Future[String] = ...
complete(result)
}
}entity(asSourceOf[T]) extracts an Akka Stream Source that can be used in the succsessive curnly bracket {...}.
Also, to let the asSourceOf directive work, we will need to define an implicit instance of akka.http.scaladsl.common.EntityStreamingSupport like we did for response streaming, which I will explain later in the article. If the implicit instance is missing, the Scala compiler will give you an error.
Define the data model for the JSON chunk
Next, we should define a data model for a JSON chunk, as a Scala case class. For simplicity, we use this DataChunk definition:
case class DataChunk(id: Int, data: String)along with the implicit instance of RootJsonFormat[DataChunk].
import spray.json.DefaultJsonProtocol._
import spray.json.RootJsonFormat
object DataChunk {
implicit val dataChunkJsonFormat: RootJsonFormat[DataChunk]
= jsonFormat2(DataChunk.apply)
}This implicit instance will be a piece of implicit resolution "puzzle" along with akka.http.scaladsl.common.EntityStreamingSupport and other implicit instances with Akka HTTP and spray-json provides.
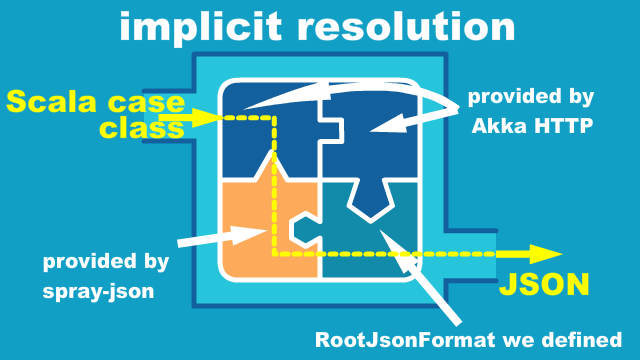
Once the puzzle is complete, Akka HTTP can convert the DataChunk case class into JSON chunk of the HTTP body, that can be transmitted over the network.
Construct the stream to run, upon each HTTP request
Now the data model for the JSON chunk is done, we should start coding the stream which runs upon arrival of each HTTP request.
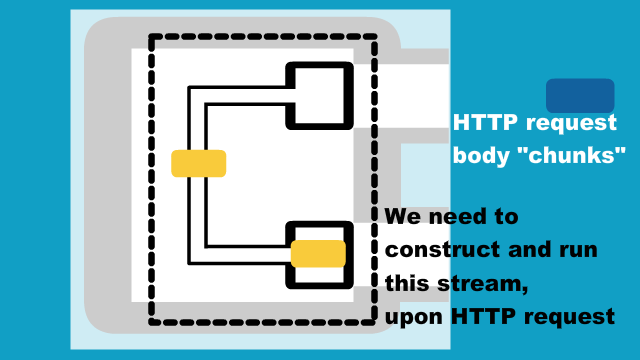
As we have seen earlier, this asSourceOf directive:
entity(asSourceOf[DataChunk]) { source => //Source[DataChunk, NotUsed]extracts an Akka Stream Source[DataChunk, NotUsed], that should be connected to the rest of the stream and run. Just for the sake of simplicity, let's define the following stream, which just counts the number of elements (i.e. number of chunks) within the HTTP request body.
val initialCount = 0
val countElement =
(currentCount: Int, _: DataChunk) => currentCount + 1
source //Source[DataChunk]
.log("received").withAttributes(
Attributes.logLevels(onElement = Logging.InfoLevel))
// count the number of elements (chunks)
.runFold(initialCount)(countElement)
// map the materialized value
.map{ count => s"You sent $count chunks" }Step-by-step description about the stream example
For those who can quickly understand what the above stream source...map{ ... } does, please skip this section. Otherwise, let me explain it a bit.
I'll demonstrate this entire example in action bit later, but we should expect this source:
source //Source[DataChunk]emits chunks like below:
// HTTP request body as JSON
// note that comments are only display purpose, as JSON doesn't allow comments
[
{"id": 1, "data": "the first" }, //1st chunk
{"id": 2, "data": "the second" }, //2nd chunk
{"id": 3, "data": "the third" }, //...
{"id": 4, "data": "the fourth" },
{"id": 5, "data": "the fifth" },
{"id": 6, "data": "the sixth" }
]
although each chunk is converted from a JSON object to a Scala case class instance of DataChunk we defined earlier.
Then the below log of operator is just for showing a log message upon each element going through this operator.
.log("received").withAttributes(
Attributes.logLevels(onElement = Logging.InfoLevel))The next step is this runFold:
val initialCount = 0
val countElement =
(currentCount: Int, _: DataChunk) => currentCount + 1
...
.runFold(initialCount)(countElement)where source. ... .runFold(initialCount)(countElement) is the Akka Stream version of the fold(Left) operation, and that will result in (i.e. materialize to) 6: Future[Int].
Since the complete() Akka HTTP directive does not take Future[Int] as the parameter, we convert it to Future[String].
// map the materialized value
.map{ count => s"You sent $count chunks" }NOTE: If you cannot tell what the above runFold does and are not familiar with Scala's fold family of methods, you can see how this can be compared to the case of plain List.
> sbt console
> import com.example.DataChunk
> val list = List(
DataChunk(1, "the first"),
DataChunk(2, "the second"),
DataChunk(3, "the thrid"),
DataChunk(4, "the fourth"),
DataChunk(5, "the fifth"),
DataChunk(6, "the sixth"),
)
> val initialCount = 0
> val countElement =
(currentCount: Int, _: DataChunk) => currentCount + 1
> list.foldLeft(initialCount)(countElement)
//you will get `res0: Int = 6`If you have, downloaded the source code, you can exacute this from an sbt console REPL session.
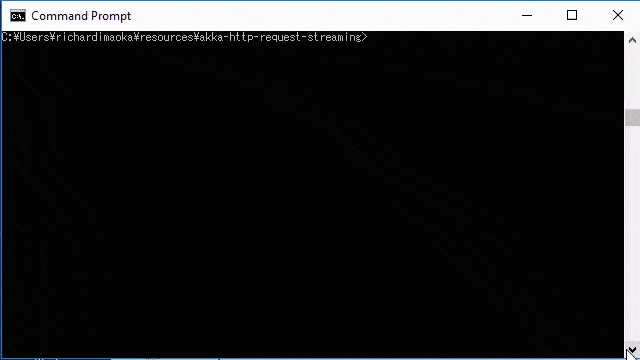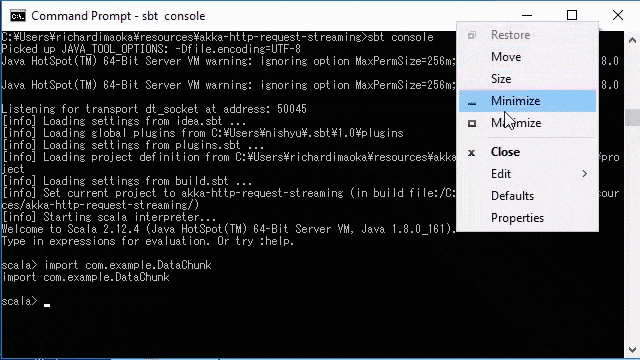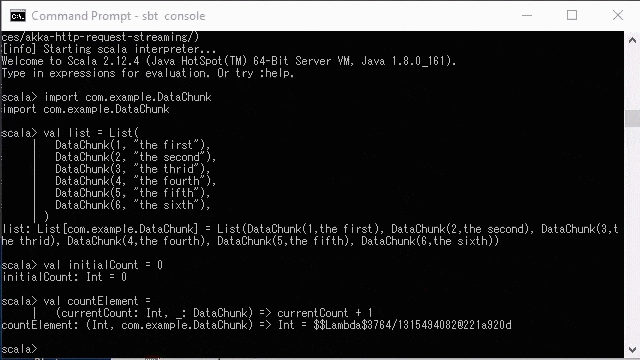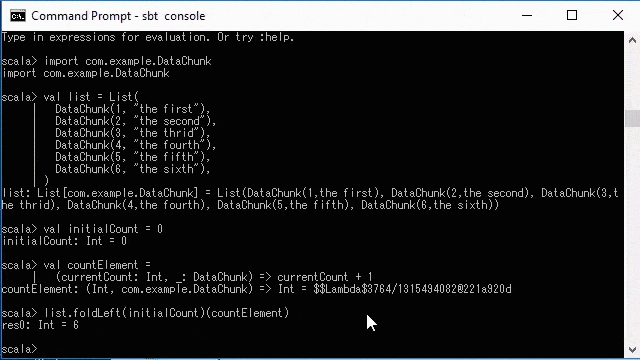
Hope this gave you the understanding of what runFold does above.
Run the stream from Route, and integrate everything
Now that we defined the stream to run upon each HTTP request, we wrap the stream definition into a class which has a method to take the Source and run:
import akka.NotUsed
import akka.actor.ActorSystem
import akka.event.Logging
import akka.stream.scaladsl.Source
import akka.stream.{Attributes, Materializer}
import scala.concurrent.{ExecutionContext, Future}
class DataProcessor(
implicit
system: ActorSystem, //this is just for implicit ExecutionContext below
materializer: Materializer
) {
def runDataSource(
source: Source[DataChunk, NotUsed]
): Future[String] = {
// This is needed for the last `map` method execution
implicit val ec: ExecutionContext = system.dispatcher
val initialCount = 0
val countElement =
(currentCount: Int, _: DataChunk) => currentCount + 1
source
.log("received").withAttributes(
Attributes.logLevels(onElement = Logging.InfoLevel))
// count the number of elements (chunks)
.runFold(initialCount)(countElement)
// map the materialized value
.map{ count => s"You sent $count chunks" }
}
}Note that the above required an implicit Materializer so that the stream can be run inside. The implicit ActorSystem is just for ExecutionContext, required for the last map method on the stream.
The complete code for the Route is as follows. Note the constructor of MainRoute below requires the dataProcessor: DataProcessor parameter, and the implicit instance of jsonStreamingSupport: JsonEntityStreamingSupport is defined.
package com.example
import akka.http.scaladsl.common.{EntityStreamingSupport, JsonEntityStreamingSupport}
import akka.http.scaladsl.marshallers.sprayjson.SprayJsonSupport._
import akka.http.scaladsl.server.Directives._
import akka.http.scaladsl.server.Route
import com.example.DataChunk._
import scala.concurrent.Future
class MainRoute(dataProcessor: DataProcessor) {
implicit val jsonStreamingSupport: JsonEntityStreamingSupport =
EntityStreamingSupport.json()
def route(): Route = post {
entity(asSourceOf[DataChunk]) { source => //Source[DataChunk]
val result: Future[String] =
dataProcessor.runDataSource(source)
complete(result)
}
}
}Lastly, the Main object is here, which passes in the DataProcessor instance to the route, and implicitly passes in the ActorSystem and ActorMaterializer to DataProcessor:
import akka.actor.ActorSystem
import akka.http.scaladsl.Http
import akka.stream.ActorMaterializer
object Main {
def main(args: Array[String]): Unit = {
implicit val system: ActorSystem = ActorSystem("Main")
implicit val materializer: ActorMaterializer = ActorMaterializer()
val dataProcessor = new DataProcessor
val mainRoute = new MainRoute(dataProcessor)
Http().bindAndHandle(mainRoute.route, "localhost", 8080)
println(s"Server online at http://localhost:8080/")
}
}If you run this example, you can see that each elements on the server side is logged due to the log operator in the stram, as on the upper window in the below demo.
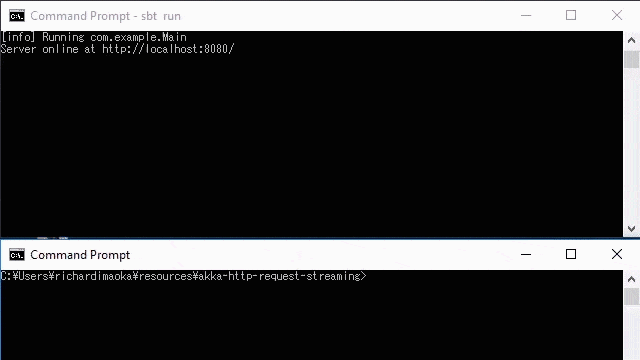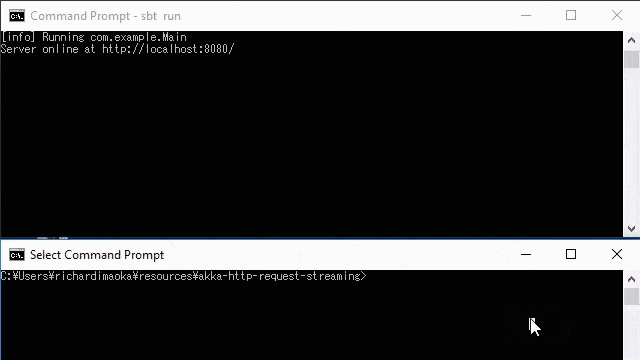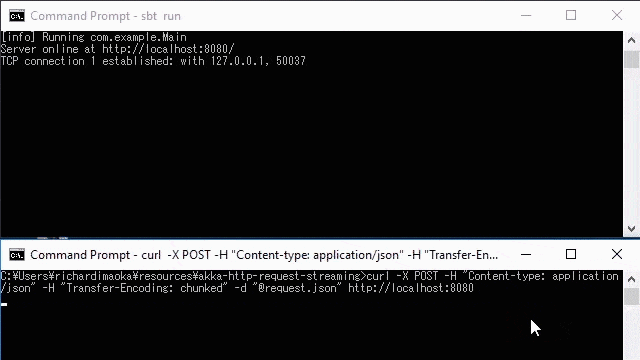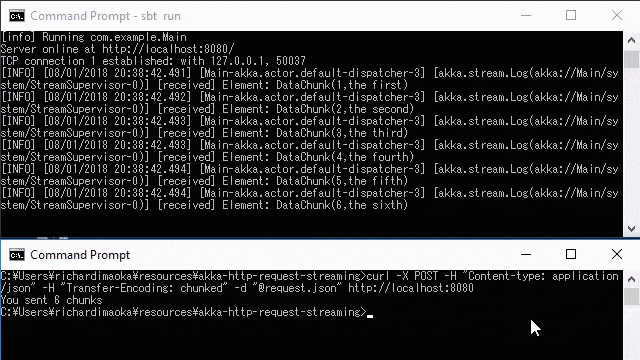
The bottom window of the below demo is the curl command, which is below:
curl
-X POST \
-H "Content-type: application/json" \
-H "Transfer-Encoding: chunked" \
-d "@request.json" http://localhost:8080where the request.json file is this:
[
{"id": 1, "data": "the first" },
{"id": 2, "data": "the second" },
{"id": 3, "data": "the third" },
{"id": 4, "data": "the fourth" },
{"id": 5, "data": "the fifth" },
{"id": 6, "data": "the sixth" }
]Again, the full source code is available here, with instruction to run the example. So if you want to see all the details, plase have a look.
Also if you liked this article, please also visit my previous Akka HTTP response streaming article too.